If you never worked with Testable before, you can check out our 10-minute introduction video here
The visual lexical decision task (V-LDT) is a versatile paradigm where participants decide whether a word is a real or not. You can use it to study the strength of mental representations in memory and understand the factors that can enhance or impede their retrieval.
The paradigm was first introduced by Meyer & Schvaneveldt (1971). In their version two words were simultaneously presented one above the other. They were interested how reading order will influence judgement about both words as a group, assuming that we usually read top to bottom. They found that participants were faster to identify both words as real, if the top word was meaningfully associated with the bottom word. This shows that the activation of a concept can spread in our brain’s network, allowing related semantic nodes to become more readily available.
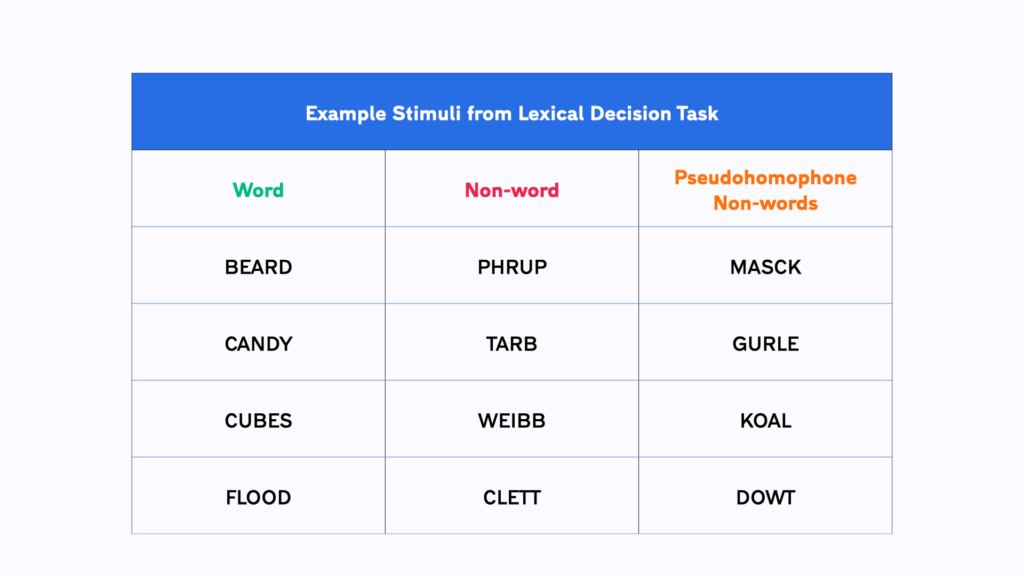
In our demo-experiment participants see one word at a time and need to decide if it is real or made up. Some of the non-words are just random (but pronounceable) strings (e.g. TARB). Others are what we call ‘Pseudohomophones’, meaning that they are non-words that sound like real words (e.g. DOWT – sounds like DOUBT). This way we can test if the phonetic representation of a word, which is misleading for pseudohomophones, can interfere with the visual judgement task. You should observe that your participants will find it harder to correctly reject the pseudohomophones. This will result in significantly larger reaction times and errors for those words than for regular non-words or real words.

In the next section we’ll dive into the nitty-gritty of the V-LDT. We will show you how you can easily run this experiment using Testable. You’ll also learn how to adapt the trial file to to create variations of this tasked, like the Go/No-Go lexical decision task or a primed lexical decision task.
In all variations of this task we measure how quickly and accurately participants decide if a word is real. This can help us to understand the mechanisms of memory retrieval. For instance, if participants judge frequent words to be real more readily than infrequent words, it shows that training can influence the strength and access speed of semantic memories. In this version of the V-LDT participants need to respond to a single word at a time using their keyboard.
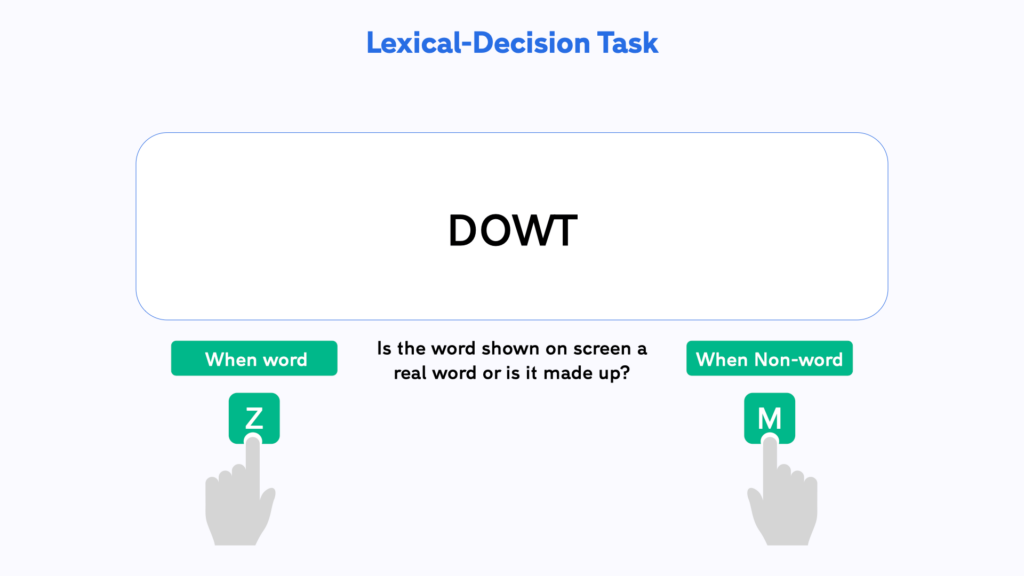
We have created a template for the VLD-T in Testable for you that you can access from our Library. It is set-up and ready to go and you can start collecting data straight away by sending the experiment link to your participant. Experiments in Testable will run in any standard browser. This makes it very easy to collect data both in the lab as well as online.
Experiments in Testable are fully customisable and you will not need to write a single line of code to edit them. The heart of each experiment is what we call the trial file. The trial file contains all information that Testable needs to run the experiment in a simple spreadsheet, that you can edit with any spreadsheet editor you like, such as Google Sheets, Excel or Testable’s in-built preview editor.
To change any part of your experiment, you only need to change the values in the trial file.
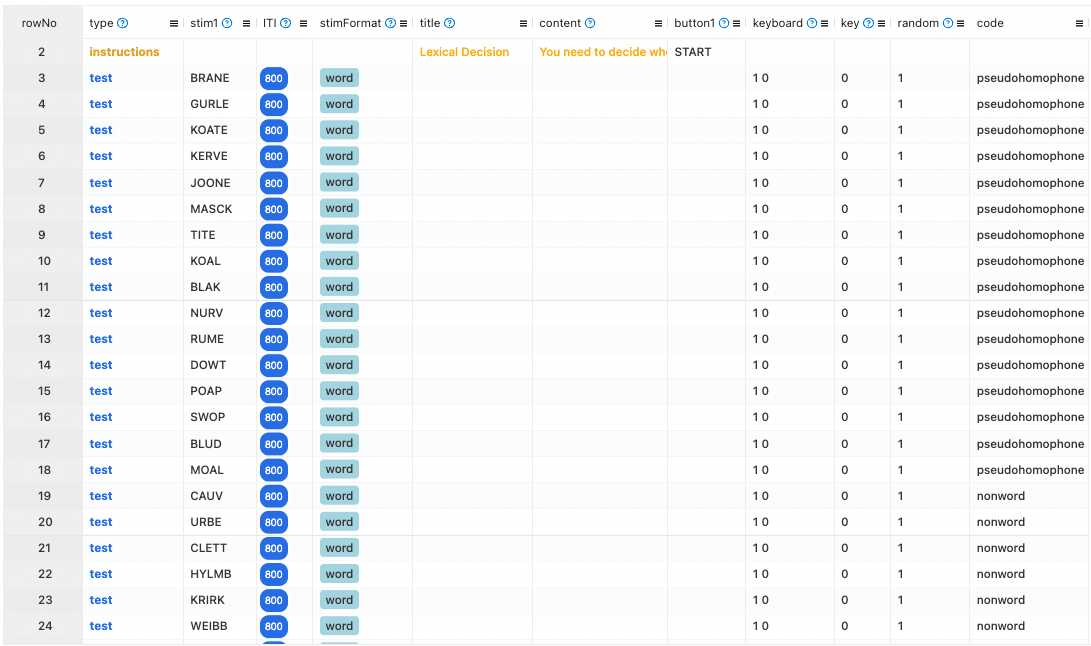
Here are a few examples of changes you might want to make to the Visual Lexical Decision Task:
Transform it into a Go/No-go decision task
In a Go/No go task participants have to respond to some trials and withhold a response to others. The correct pairing for “Go” and “No-Go” responses is shown upfront and needs to be counterbalanced. Usually, a larger number of trials are “Go” trials in the experiment makes it more difficult to abstain from responding on “No-Go” trials. In our example we expect the error rate on ‘No-Go’ trials to be higher for pseudohomophone non-words. This is because they interfere with the correct response by partially activating the incorrect (Go) response associated with real words.
To allow participants to progress through the trials even with “No-go” responses, we must first limit the presentation time for our stimuli. This is important to allow for the ‘No-go’ response where trials advance without participant input. You can create a new column in the spreadsheet called responseWindow. Here you can specify how long participants can respond before the next trial is shown automatically. A value of 2000 means that responses are accepted for 2 seconds (2000ms) before the trial times out.
In the keyboard column you should only allow the single button that is allowed on ‘Go’ trials. Finally, you should adjust the values in the key column, which code the correct response that allows automatic accuracy recording. Here you need to define correct responses as a keypress on “Go” trials and no keypress (blank) on “No-go” trials.
Transform it into a Semantic Priming task
A common variation of the lexical decision task involves showing a brief prime before the target word. The primes could be related in some way to the target (i.e. DOCTOR → NURSE) or unrelated (DOG → SINK). Participants barely notice primes with brief presentation times. Yet, they can usually boost responses for semantically related, but not for unrelated words. These findings support connectionist models which assume that the activation of a concept in memory (the prime) spreads to neighbouring concepts (associated target).
To present primes you will need to allow each trial to sequentially present multiple stimuli. This can easily done by adding the following three columns:
Now each trial will begin with a brief, 66ms, presentation of the prime word, that is immediately followed by the target. Participants can respond with the usual keys as in the original task.
After importing this template to your library, you can collect data for your experiment by sharing the unique experiment link (i.e. tstbl.co/xxx-xxx) with your participants. Once participants complete the experiment, their results will appear in the ‘Results’ section of your experiment.
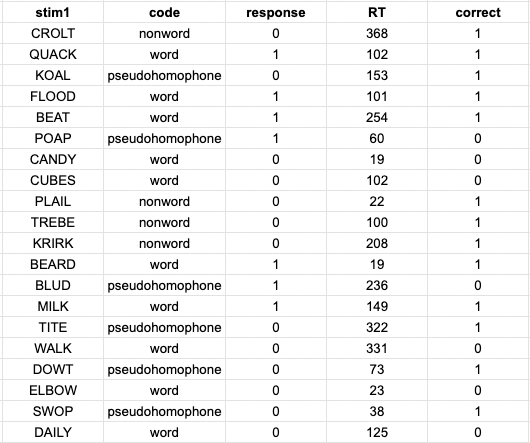
This version of the V-LDT automatically measures the response time (RT column) and accuracy (correct column) of deciding whether a word is real or not on each trial.
In the trial file we have defined a column called code with the possible values ‘word’, ‘nonword’ and ‘pseudohomophone’. This column has no bearing on the logic of the experiment, but comes handy for analysis, as we can now easily group the response times and accuracies by their experimental condition and calculating their mean values.
You should see that participants take longer to reject non-words than accept real words. Likely, the most interesting effect will be the increased error rate and longer response times for pseudohomophone trials. The misleading phonologic representation of these non-words interfere in the decision task as they are automatically elicited in the participants’ mind.
Once you have collected data from multiple participants, you can also use Testable’s ‘wide format’ feature, that automatically collates all individual result files into a single file. In this file every participant’s data takes up one row. This makes it easily compatible with statistical analysis packages like R or SPSS where you can assess the statistical significance of any differences you may find
Reference list:
Meyer, D. E. (6). & Schvaneveldt, RW (1971). Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. Journal of Experimental Psychology, 90(2), 227-234.
Moret-Tatay, C., & Perea, M. (2011). Is the go/no-go lexical decision task preferable to the yes/no task with developing readers?. Journal of experimental child psychology, 110(1), 125-132.
Perea, M., & Rosa, E. (2002). The effects of associative and semantic priming in the lexical decision task. Psychological research, 66(3), 180-194.